Data quality issues have been a long-standing challenge for data-driven organizations. Even with significant investments, the trustworthiness of data in most organizations is questionable at best. Gartner reports that companies lose an average $14 million per year due to poor data quality.
Data Observability has been all the rage in data management circles for a few years now and has been positioned as the panacea to all data quality problems. However, in our experience working with some of the world’s largest organizations, data observability has failed to live up to its promise.
The reason for this is simple: data integrity problems are often caused by issues that occur at the “last mile” of the data journey – when data is transformed and aggregated for business or customer consumption.
In order to improve data quality effectively, Data observability needs to detect the following three types of data errors:
- Meta Data Error (First Mile Problem): This includes things like detecting freshness, changes in record volume, and schema changes. Metadata errors are caused by incorrect or obsolete data, changes in the structure of the data, a change in the volume of the data, or a change in the profile of the data.
- Data Error ( Middle Mile Problem): This includes things like detecting record-level completeness, conformity, uniqueness, anomaly, consistency, and violation of business-specific rules.
- Data Integrity Error (Last Mile Problem): This includes things like detecting loss of data and loss of fidelity between source and target system.
However, most data observability projects/initiatives only focus on detecting Meta Data Errors. As a result, these initiatives fail to detect Data Integrity Errors – which impact the quality of the financial, operational, and customer reporting. Data integrity errors can have a significant impact on business, both in terms of cost and reputation.
Data integrity errors are most often caused by errors in the ETL process and incorrect transformation logic.
Current Approach for detecting data integrity errors and Challenges
Most data integrity initiatives leverage the following types of data integrity checks:
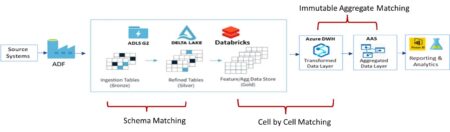
- Schema Checks: It checks for schema and record count mismatches between source and target systems. This is a very effective and computationally cheap option when data does not undergo any meaningful transformations. Generally used during migration projects or data refinement processes as depicted in the data flow
- Cell by Cell Matching: Data often undergoes transformations throughout its journey. In this scenario, cell-by-cell matching of data elements between the source and target system is done to detect data loss or data corruption issues.
- Aggregate Matching: Data is often aggregated or split for business or financial reporting purposes. In this scenario, one-to-many matching of the aggregated data elements between the source and target system is done to detect data loss or data corruption issues due to aggregation errors.
Most data team experiences the following operational challenges while implementing data integrity checks:
- Time it takes to analyze data and consult the subject matter experts to determine what rules need to be implemented for a schema check or cell-by-cell matching. This often involves the replication of transformation logic.
- Data needs to be moved from the source system and target system to the data integrity platform for matching resulting in latency, increased compute cost , and significant security risks. [2,3]
Solution Framework
Data teams can overcome the operational challenges by leveraging machine learning-based approaches:
- Finger Printing Technique: Traditional Brute force data matching algorithms becomes computationally prohibitive to match all source records with all target records when the data volume is large.
Fingerprinting mechanisms can be used to identify if two data sets are identical without the need to compare each record in the data set. A fingerprint is a small summary of a larger piece of information. The key idea behind using fingerprints for data matching is that two pieces of information will have the same fingerprint if and only if they are identical. There are three types of advanced fingerprinting mechanisms – Bloom filters[1], Min-Hash, and Locality Sensitive Hashing (LSH).
Fingerprinting techniques are computationally cost-effective and do not suffer from scalability problems. More importantly, fingerprinting technique eliminates the need to move the source and target system data to another platform.
- Immutable Field Focus: Cell-by-cell matching should focus only on immutable data elements – business-critical columns that do not change or lose their meaning because of transformation. For example, the total principal loan amount of a mortgage should remain unchanged between the source and target system irrespective of the transformation. Matching all data fields requires replication of the transformation logic which is time-consuming.
- Autonomous Profiling: Autonomous means for identifying and selecting immutable fields help data engineers focus on the most important data elements that need to be matched between the source and target system. When these critical fields are matched successfully, it is likely that the entire record has been transformed correctly.
Conclusion
So, is data observability the silver bullet for all data quality problems? In short, no. However, if you are experiencing data integrity issues at the “last mile” of your data journey, it is worth building a data observability framework that not only detects metadata errors but also data errors and data integrity errors. Automated machine learning can be leveraged to eliminate the operational challenges associated with traditional data integrity approaches.
[1] https://arxiv.org/pdf/1901.01825.pdf
[2] https://www.datafold.com/blog/open-source-data-diff
[3] https://firsteigen.com/blog/how-to-ensure-data-quality-in-your-data-lakes-pipelines-and-warehouses/